
Understanding the origins and transformations of data is critical for effective management, analysis, and decision-making. Data lineage plays a vital role in this process, providing insights into data’s lifecycle and ensuring data quality, traceability, and compliance.
In this post, we will delve into the concept of data lineage and explore how CI/CD data can be effectively utilised and integrated into data lineage management. By the end of this post, you will have a clear understanding of data lineage and the benefits of implementing the concept inside CI/CD.
What is Data Lineage?
Data lineage is the process of tracking the movement, transformation, and usage of data throughout its lifecycle within an organization’s data ecosystem.
It provides a comprehensive view of where data originates, how it changes over time, and where it is consumed. By maintaining accurate data lineage, organizations can ensure data quality, traceability, and compliance with various regulations.
How Data Lineage Works
Data lineage works by capturing and documenting the movement of data as it flows between systems, applications, databases, and reporting tools. Each transformation, integration, or processing step is recorded, creating a traceable path from the original source to the final destination.
For example, customer information might originate in a CRM platform, be transformed within a data warehouse, and ultimately appear in dashboards or reports used by business stakeholders. Data lineage allows teams to understand each step in that journey and identify where changes, errors, or quality issues may have occurred.
Modern data lineage solutions often automate the discovery and mapping of data flows, reducing the effort required to maintain accurate documentation and improving visibility across complex environments.

History of Data Lineage
Data lineage has a long history, dating back to the early days of computer programming. The concept of data lineage emerged in the 1970s, when the first data processing systems were developed. At that time, data lineage was primarily used for data auditing purposes, helping organizations to track the flow of data through their systems.
Over time, data lineage has evolved and become more sophisticated, with the development of new technologies and tools that enable more comprehensive tracking and analysis of data. In the 1990s, data lineage became a key component of enterprise data management, as organizations sought to better understand how data was being used across their operations.
With the rise of big data and the increasing complexity of data management, data lineage has become even more important in recent years. Today, data lineage is a critical component of the software development lifecycle, enabling teams to track the flow of data throughout the development process and ensure that data is accurate, consistent, and of high quality.
As technology continues to evolve and data becomes even more central to business operations, the importance of data lineage is only likely to grow. With the right tools and strategies in place, organizations can leverage the power of data lineage to drive better outcomes and achieve their goals.
Understanding Data Lineage
Having established what it is, and where it came from, let’s examine its significance and some benefits that it furnishes an organization.
Importance of Data Lineage
Data lineage is essential in modern data management for several reasons:
- Data Governance: Effective data governance requires a thorough understanding of data flow across an organization. Data lineage helps in creating an inventory of data assets, enforcing data policies, and managing data access controls.
- Data Quality: Accurate data lineage helps identify and address data quality issues by highlighting discrepancies, inconsistencies, and inaccuracies in the data as it moves through various stages of processing.
- Compliance: Many regulatory requirements, such as GDPR and HIPAA, demand a comprehensive understanding of data flow and usage. Data lineage helps organizations meet these requirements by providing transparency and traceability of data handling processes.
- Impact Analysis: Data lineage enables organizations to assess the potential impact of changes in data sources, processes, or systems by understanding the dependencies between data assets and their consumers

Benefits of Maintaining Accurate Data Lineage
Implementing data lineage practices in your organization can result in several benefits:
- Improved Decision Making: With a clear understanding of data’s origins and transformations, organizations can make informed decisions based on accurate and trustworthy data.
- Increased Efficiency: Accurate data lineage helps in identifying and eliminating redundant or unnecessary data processing steps, reducing operational costs and improving overall efficiency.
- Enhanced Collaboration: Data lineage provides a shared understanding of data assets and their relationships, fostering better collaboration between different teams within an organization.
- Risk Mitigation: Understanding data lineage helps organizations proactively identify and address potential risks associated with data handling, minimizing the chances of data breaches or non-compliance with regulatory requirements.
Types of Data Lineage
Organizations typically use different approaches to data lineage depending on their requirements and technology landscape.
1. Business Lineage
Business lineage focuses on understanding data from a business perspective. It helps stakeholders understand how information supports business processes, reporting, and decision-making.
2. Technical Lineage
Technical lineage focuses on the systems, databases, applications, and integrations that move and transform data. This view is commonly used by developers, architects, and operations teams to troubleshoot issues and assess the impact of system changes.
3. Operational Lineage
Operational lineage tracks the execution of processes and workflows over time. This can provide valuable insight into deployment activities, data movement, and CI/CD pipeline execution.
Together, these different views help organizations build a complete understanding of how data moves throughout the enterprise.
What is CI/CD?
Continuous Integration and Continuous Deployment (CI/CD) is a software development methodology that emphasizes the automation of the software development lifecycle. CI/CD consists of two primary components: Continuous Integration and Continuous Deployment.
Continuous Integration is the practice of regularly merging code changes from multiple developers into a shared code repository. The goal of Continuous Integration is to ensure that all changes to the codebase are tested and integrated as quickly as possible, to catch any issues early and reduce the likelihood of conflicts arising when changes are merged together.
Continuous Deployment is the practice of automating the deployment of software changes to production environments. The goal of Continuous Deployment is to make the process of deploying software as quick, reliable, and repeatable as possible, to reduce the risk of errors and minimize downtime.
CI/CD pipelines are typically implemented using a combination of tools and services, including version control systems, automated build and test systems, containerization technologies, and cloud-based infrastructure. These tools and services enable developers to quickly and easily test and deploy changes to their code, while also providing visibility into the status of the development and deployment processes.
CI/CD has become an essential part of modern software development practices, as it enables teams to rapidly develop and deploy high-quality software, while also reducing the risk of errors and downtime. By automating key parts of the software development lifecycle, CI/CD helps teams to focus on what they do best: writing great code.
CI/CD Data Points
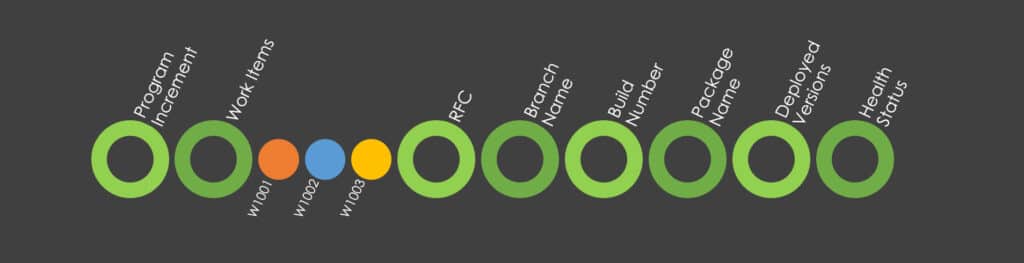
As part of tracking your Software Development Lifecycle, or CI/CD, there are several key insights, data points, that can be captured to help ensure the success of the software development process. To support the concept of Data Lineage, this may include the capture of date like:
- Program Increment (PI) Name: PI is a timebox in which a set of development objectives are achieved. It is a planning and execution cadence used by Agile organizations to deliver value in a consistent and predictable manner. Tracking PI progress can help teams understand how development objectives are progressing, and identify any risks or issues that may need to be addressed.
- Work Items: Work Items (like stories, debts and defects) are specific tasks or issues that need to be completed as part of the development process. Tracking work items can help teams understand the progress of specific tasks, identify any bottlenecks or issues that may be slowing down the development process, and ensure that all work is completed in a timely manner.
- Request for Change (RFC): Tracking the RFC number associated with each code change can help ensure that all changes are properly documented and reviewed before they are merged into the codebase. This can help catch potential issues early in the development process and reduce the risk of conflicts or errors.
- Branch Name: Branches are typically used to develop new features, perhaps specified in the RFC, or make changes to existing functionality without affecting the main codebase. Once a branch is created, developers can work on the new feature or change without interfering with the main codebase.
- Build Number: Assigning a unique build number to each code build can help track changes over time and ensure that each build is properly versioned. This can also help with troubleshooting and identifying the source of issues.
- Package Name: Tracking the name of the package associated with each build can help ensure that the correct version of the software is deployed to each environment.
- Deployed Versions: Different teams may use different deployment strategies. Tracking the deployed versions of software across different environments can ensure that all environments are consistent and operating properly. It’s also important to identify the target systems, such as SIT, UAT, and Staging, to ensure that all engineering efforts are aligned and changes are thoroughly tested and validated before being released to production.
- Health Tests: Capturing the results of automated health tests for each build and deployment can help ensure that the software is working as expected and that any issues are quickly identified and addressed.
By tracking these key insights, inherent to the CI/CD process, teams can ensure that their software development process is efficient, effective, and delivers high-quality software to their customers. It can also ensure you can track data, and the sub-items produced, from concept to delivery.
Tools Used in CICD Data Lineage
Here are some example tools, in chronological order, that might be used in a typical CI/CD pipeline:
- Git: Developers use Git for version control to track changes made to code, including the associated branch/trunk details.
- Jira: Jira is a popular project management tool used to track work items such as user stories, bugs, and technical tasks throughout the development process.
- Jenkins: Jenkins is an open-source automation server that can be used to automate the software build and deployment process. It assigns unique build numbers and tracks health test results.
- Artifactory: Artifactory can be used to store and manage all types of binary artifacts, including container images, JAR files, RPM packages, and more. It provides a centralized platform for storing and distributing artifacts across an organization’s development and deployment environments.
- SonarQube: SonarQube is a tool for continuous code quality inspection and static analysis. It can be used to track code quality metrics and identify potential issues early in the development process.
- Docker: Docker is a containerization platform that can be used to package and deploy software. It can be configured to track package names and the environments to which software is deployed.
- Kubernetes: Kubernetes is a container orchestration platform that can be used to deploy and manage software in a scalable and reliable manner. It can be configured to track deployments to different environments.
By utilizing these tools in a CI/CD pipeline, organizations can ensure data lineage by tracking key data points such as program increments, work items, RFC, build numbers/names, package numbers, targets deployed to, and health checks & targets tested throughout the development process.
Enov8 for CICD Data Lineage
Enov8’s out-of-the-box solution, “Platform Insights,” can support data lineage reporting by integrating with the various tools used in a typical CI/CD pipeline. By integrating with tools such as Git, Jira, Jenkins, Artifactory, SonarQube, Docker, and Kubernetes, Enov8 can help organizations track key data points such as program increments, work items, RFC, build numbers, package numbers, targets deployed to, and health checks & targets tested throughout the development process.
With Enov8’s platform insights, organizations can easily view and report on the status of their software development projects, identify any bottlenecks or issues, and ensure data lineage is maintained throughout the process. The platform can also provide analytics and insights on the performance of the development process, allowing teams to make data-driven decisions to improve efficiency and quality.
Enov8 Information Wall, CICD Lineage: Screenshot

Benefits of Data Lineage in CICD
Data insights and data lineage can provide several key benefits for the Software Delivery Lifecycle & CICD, including:
- Improved decision-making: By providing real-time data insights into the software development process, teams can make informed decisions about the direction of the project. This can help identify areas of the development process that may need improvement, and enable teams to make data-driven decisions that result in better outcomes.
- Enhanced quality control: Data lineage can help ensure that data is accurate, consistent, and of high quality. By tracking the origin of data and how it is transformed throughout the development process, teams can identify and address any issues that may impact the quality of the software.
- Increased transparency: Data insights and data lineage can help increase transparency into the software development process, providing visibility into how data is being used and manipulated. This can help improve communication and collaboration between teams, and enable stakeholders to make more informed decisions about the project.
- Improved compliance: Data lineage can help ensure that data is compliant with regulatory requirements and industry standards. By tracking the lineage of data throughout the development process, teams can identify any areas where compliance may be at risk, and take corrective action before issues arise.
- Better risk management: By providing visibility into the flow of data throughout the development process, teams can identify potential risks and take proactive measures to mitigate them. This can help reduce the likelihood of errors, delays, or other issues that could impact the success of the project.
Conclusion
In conclusion, data lineage plays a critical role in ensuring the success of the CI/CD process, enabling teams to make informed decisions, improve quality control, increase transparency, ensure compliance, and better manage risk.
As a Platform of Insight, Enov8 is one such tool that can help achieve these goals, providing teams with real-time data insights and data lineage capabilities that enable them to track the flow of data throughout the software development process. With Enov8, teams can gain a better understanding of how data is being used and manipulated, identify potential issues before they arise, and make data-driven decisions that result in better outcomes.
By leveraging the power of data lineage, teams can ensure that their software delivery processes are efficient, effective, and successful.

Post Author
Niall Crawford is the Co-Founder and CIO of Enov8. He has 25 years of experience working across the IT industry from Software Engineering, Architecture, IT & Test Environment Management and Executive Leadership. Niall has worked with, and advised, many global organisations covering verticals like Banking, Defence, Telecom and Information Technology Services.