
Data security and protection of “Personally Identifiable Information” is crucial, independent of whether the information is held in a file, a database, or as ‘big data’ in a data lake.
In this article, we will explore the characteristics of data and security from the perspective of the data lake.
What is a Data Lake?
A data lake is a centralized repository for storing all types of data, both structured and unstructured. It is designed to be a single source of truth for all your data, meaning that it eliminates the need to scatter your data across multiple systems.
This reduces storage costs and increases accuracy by reducing duplicate data. Additionally, a data lake provides a platform where data scientists and analysts can run big data analytics and machine learning algorithms, allowing organizations to make more informed decisions.
When setting up a data lake in the Hadoop ecosystem, the HDFS file system is typically used. However, some cloud providers have replaced it with their own deep storage solutions such as S3 or GCS.
When choosing the right file format for deep storage, it is important to consider the ACID* properties since these file systems are cheaper than databases but do not offer strong ACID guarantees.
*ACID stands for Atomicity, Consistency, Isolation, and Durability. It is a set of properties that guarantee that database transactions are processed reliably.
Depending on your needs and budget, you can choose between a database for ingestion or storing all of your data in a deep storage system. If you have the resources available, you can also keep a small subset of hot data in a fast storage system such as a relational database.

Data Lake File Formats
It is essential to familiarize yourself with the importance of proper storage for deep data systems.
This includes carefully considering file format, compression, and partitioning tactics so that when organizing your data lake, you can enjoy maximum efficiency from all benefits available.
Popular formats such as AVRO, CSV, JSON, ORC, and Parquet are widely used in data streaming.

File Format Options
Some things to consider when choosing the format are:
1. Structure of Data
When dealing with Big Data, it is important to consider the structure of the data. Some formats such as JSON, Avro, or Parquet are optimized for nested data and can provide better performance than other formats.
Avro is the most efficient format for nested data, while Parquet is a column-based format that is great for querying with SQL. It is recommended to flatten the data when ingesting it into a Big Data lake.
2. Performance
Different formats offer different levels of performance when dealing with Big Data. Avro and Parquet are two of the most performant formats, but one may be better suited for certain use cases than others.
For example, Parquet is great for querying with SQL while Avro is better for ETL row-level transformation.
3. Readability
If people need to read the relevant data, then JSON or CSV are text formats that are human readable, whereas more performant options such as Parquet or Avro are binary.
4. Compression
Some formats offer higher compression rates than others, which can help reduce storage costs when dealing with large amounts of Big Data.
5. Schema Evolution
Adding or removing fields in a Big Data lake can be complicated, and some formats such as
Avro or Parquet provide some degree of schema evolution, which allows you to change the data schema and still query the data. Tools such as the Delta Lake format provide even better tools to deal with changes in Schemas.
6. Compatibility
JSON or CSV are widely adopted and compatible with almost any tool, while more performant options have fewer integration points when dealing with Big Data.
File Formats Types
1. CSV
Good option for compatibility, spreadsheet processing, and human-readable data, CSV is a great choice for exploratory analysis, POCs, or small data sets. However, it is not efficient and cannot handle nested data, so it may not be the best choice for large-scale Big Data projects.
2. JSON
Heavily used in APIs, JSON is a great format for small data sets, landing data, or API integration. It is widely adopted and human readable but can be difficult to read if there are lots of nested fields.
3. Avro
Avro is an efficient format for storing row data with a schema that supports evolution. It works well with Kafka and supports file splitting, making it ideal for row-level operations or in Kafka-based Data Lakes.
4. Parquet
Parquet is a columnar storage format that has schema support and works well with Hive and Spark as a way to store columnar data in deep storage that can be queried using SQL in Big Data projects.
5. ORC
ORC is similar to Parquet but offers better compression and better schema evolution support. It is less popular than Parquet but still useful in Big Data projects where compression and schema evolution are important considerations.
Big Data File Comparison Table
| Feature | Avro | JSON | ORC | Parquet |
| Format | Binary | Text | Binary | Binary |
| Schema | Avro schema is required | No schema is required | ORC schema is required | Parquet schema is required |
| Compression | Supports many compression algorithms | No built-in compression | Supports several compression algorithms including Snappy, Zlib, and LZO | Supports several compression algorithms including Snappy, Gzip, and LZO |
| Performance | Fast serialization and deserialization | Slower serialization and deserialization due to text format | Fast reading and writing performance | Fast reading and writing performance with columnar storage format |
| Interoperability | Avro is language-agnostic, providing support for multiple programming languages | JSON is supported by many programming languages | ORC format is specific to the Hadoop ecosystem | Parquet is supported by many big data tools and frameworks |
| Use cases | Best for data serialization and storage | Best for human-readable data exchange | Best for fast querying and analysis of big data | Best for columnar storage and data analytics |
Data Lake File Compression
Data lake file compression refers to the process of reducing the size of data stored in a data lake, a large repository of structured and unstructured data, for more efficient storage and faster data retrieval.
Compression helps organizations to reduce the cost of data storage and improve the speed of data access.
There are several types of data processing compression techniques that can be applied to data stored in a data lake:
1. Lossless Compression
This type of compression reduces the size of data without losing any information. Lossless compression techniques include run-length encoding and Huffman coding.
2. Lossy Compression
This type of compression reduces the size of data by sacrificing some information. Lossy compression techniques include image compression and audio compression.
3. Columnar Compression
This type of compression is used for storing data in a columnar format, where each column is compressed separately. This technique is commonly used in columnar databases, as it allows for faster query processing.
4. Dictionary Encoding
This type of compression uses a dictionary of values to replace repeated values in a column, reducing the size of the data.
Organizations can choose the type of compression that best meets their needs based on the nature of their data and the desired trade-off between compression ratio and data quality.
It is important to note that compression may introduce additional processing overhead, as the data must be decompressed before it can be used. To minimize this overhead, data lake systems often employ techniques such as lazy decompression, where the data is decompressed only when it is needed for processing.
Ultimately, there is no one-size-fits-all solution when it comes to file compression; each situation requires careful consideration of both file size and CPU costs in order to select the most appropriate algorithm for the task at hand.
To learn more about this topic in depth, please refer to this helpful article.
Data Lake Security
Big Data Security Needs
Data security is critical in data lakes, especially in non-production environments, for several reasons:
1. Confidentiality
Data lakes often store sensitive and confidential information, such as financial or personal information. It’s important to ensure that this information is protected and only accessible to authorized personnel.
2. Compliance
Certain industries have strict regulations for storing and processing data, such as the healthcare industry’s HIPAA or the financial industry’s FINRA. Failure to comply with these regulations can result in hefty fines and damage to the company’s reputation.
3. Protecting intellectual property
Data stored in a data lake can be a company’s valuable intellectual property. Ensuring that this data is protected and secure helps to prevent unauthorized access and potential theft of the company’s proprietary information.
4. Protecting against cyberattacks
Data lakes can be targeted by cybercriminals, who may attempt to steal or manipulate the data. Implementing proper security measures helps to prevent these types of attacks and protect the data stored in the data lake.
Simply put, data security is essential in data lakes, especially in non-production environments, to ensure confidentiality, compliance, protection of intellectual property, and prevention of cyberattacks.
Big Data Security Methods
There are several methods that can be used to secure a data lake in non-production environments:
1. Data Masking
Data Masking is a process where sensitive information is replaced with fake data that preserves the format, structure, and length of the original data, but obscures its content.
Data masking can be used to secure sensitive information stored in a data lake and ensure that it is only accessible to authorized personnel.
2. Fake Data
Using fake data in a non-production environment is another way to secure sensitive information stored in a data lake. This can help to prevent unauthorized access and protect the confidentiality of sensitive information.
3. Access Control
Implementing proper access control measures is critical in securing a data lake.
This can include using authentication and authorization mechanisms, such as username and password authentication or role-based access control, to ensure that only authorized personnel have access to the data.
4. Encryption
Encrypting the data stored in a data lake helps to protect the confidentiality of sensitive information and prevent unauthorized access. Encryption can be applied to data at rest, in transit, or both.
5. Data Auditing
Keeping a record of all access to the data in a data lake can help to detect any unauthorized access or potential security breaches. Data auditing can also be used to monitor the activities of authorized personnel to ensure they are following proper security procedures.
Tip! Implementing a combination of these measures can help to ensure the security and protection of sensitive information stored in a data lake.
Types of Data to Secure
The following are some examples of the types of data that should be secured inside a data lake and in non-production* data lakes.
- Intellectual property, such as source code, algorithms, and trade secrets.
- Confidential business information, such as financial projections, business plans, and contracts.
- Personal data, such as employee or customer information, that may contain sensitive information such as Social Security numbers, addresses, and financial information.
- Compliance data, such as data that is subject to regulations like the GDPR, HIPAA, or the CCPA.
*A non-production data lake is typically used for testing, development, and other activities that don’t involve live production data. However, it can still, and often does, contain sensitive information that requires protection.
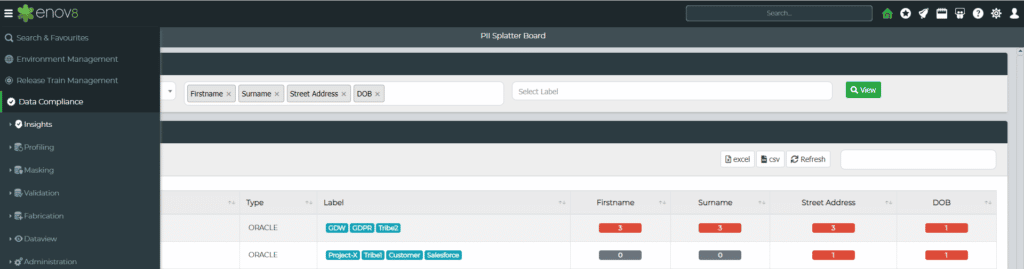
Enov8 Test Data Manager, A Data Discovery & Securitization Platform: Screenshot
Conclusion
In conclusion, it is essential to understand the importance of proper storage and file formats when dealing with Big Data. Different formats offer different levels of performance and compatibility, so it is important to select the right format for your use case.
Additionally, when compressing data, CPU costs should be taken into consideration in order to select the most appropriate algorithm for the task at hand.
Furthermore, data security measures such as data masking, fake data, access control, encryption, and data auditing can help secure a data lake and protect sensitive information stored within it.
By better understanding Data Lakes and following these best practices, companies can ensure maximum efficiency from all available benefits while protecting their valuable information.

Author Jane Temov
Jane Temov is an IT Environments Evangelist at Enov8, specializing in IT and Test Environment Management, Test Data Management, Data Security, Disaster Recovery, Release Management, Service Resilience, Configuration Management, DevOps, and Infrastructure/Cloud Migration. Jane is passionate about helping organizations optimize their IT environments for maximum efficiency.