There’s a quiet assumption baked into a lot of synthetic data strategies: if you need test data, you generate it. All of it, from scratch, every time.
It feels like the modern, AI-powered answer to test data. But it’s often the slow, expensive answer to a problem that’s usually much smaller than it looks.
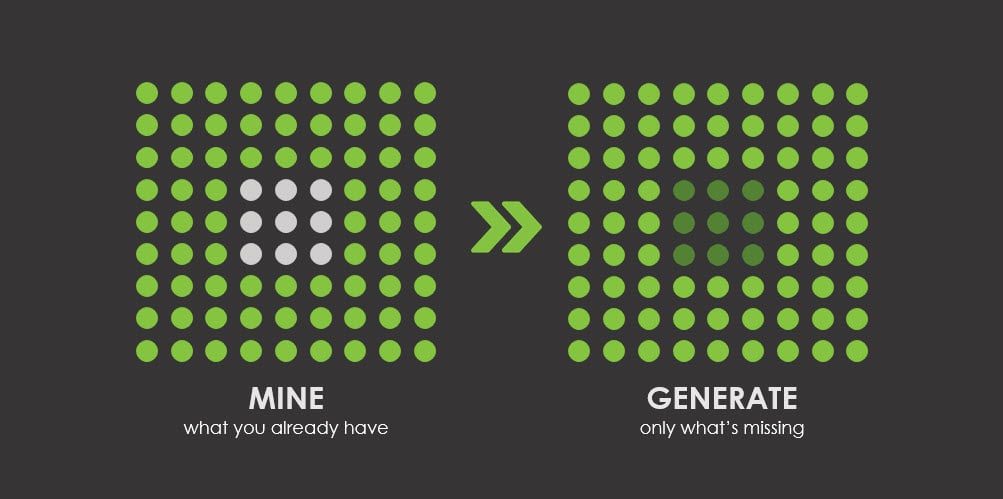
The 95% problem
Here’s the reality most test data teams run into: the data you need already exists somewhere in your environment landscape. A customer record with the right risk profile. A claims history with the right edge case. An account with the right balance and transaction pattern. It’s sitting in a lower environment, in a data warehouse, in last quarter’s refresh, waiting to be found.
In our experience, around 95% of the time, the data a tester needs already exists. The real problem isn’t a lack of data, it’s a lack of visibility into what you already have and a fast way to locate and provision it.
Generating that 95% from nothing isn’t just wasted effort. It introduces risk: synthetic records can miss the subtle relationships, referential integrity, and real-world messiness that make a test meaningful in the first place.
So what about the other 5%?
This is where generation earns its place, not as the default, but as the fallback.
When the data genuinely doesn’t exist, when there’s no real-world example of that fraud pattern, that compliance edge case, or that rare combination of attributes, that’s when you generate. Purpose-built, on-demand, and only for the gap.
This is the thinking behind Enov8’s TDM Data Factory model: Mine, Book, Generate, Subset.
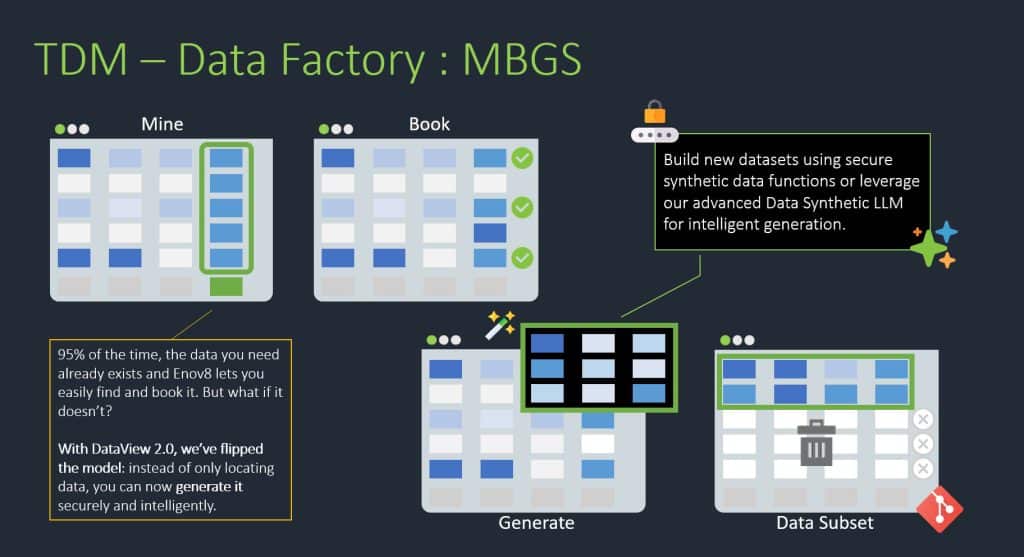
- Mine the data you already have. Search across environments and datasets to surface records that match what’s needed, instead of starting from zero.
- Book it. Once a matching dataset is found, reserve it so it’s protected for the test that needs it, no overwrites, no conflicts with other teams.
- Generate, only when something is missing. Use secure synthetic data functions, or an LLM-driven data synthesis engine, to intelligently fill the gap, not replace the whole dataset.
- Subset what’s relevant. Pull a right-sized, targeted extract rather than dragging an entire dataset into a test environment that only needs a slice of it.
Why order matters
Flip the model around and generate everything first, and you’ve created a new problem: you now have to validate that synthetic data behaves like real data, manage its lifecycle, and explain to auditors why your test environment is full of records nobody can trace back to a real business scenario.
Mine first, and you inherit data that’s already realistic, already compliant with how your systems actually behave, and already representative of genuine customer and transaction patterns. Generation becomes a precision tool for closing specific gaps rather than a blunt instrument for building an entire dataset.
The result is faster provisioning (you’re searching and booking, not waiting on a generation job), lower risk (less synthetic data to govern and secure), and better test coverage (real data plus precisely generated edge cases beats either approach alone).
The takeaway
Synthetic data generation is a powerful capability, but it’s most powerful when it’s targeted. The question worth asking isn’t “how do we generate the data we need?” It’s “what data do we actually have, and what’s truly missing?”
Mine what exists. Book it so it’s protected. Subset it down to what’s relevant. And generate only the gap.
That’s not a smaller vision for test data management. It’s a more disciplined one, and it’s why we built Data Factory around it.