
If you are looking for a definition of data masking, its types, and how it compares to encryption and tokenization, read our What is Data Masking? guide first. This article assumes you know what masking is and answers the harder question: how do you actually implement it, at enterprise scale, without breaking your applications or your delivery timelines?

The Enterprise Data Masking Workflow
Successful masking programs are not a single transformation script. They are a pipeline, and every stage exists because skipping it causes a specific, predictable failure later.
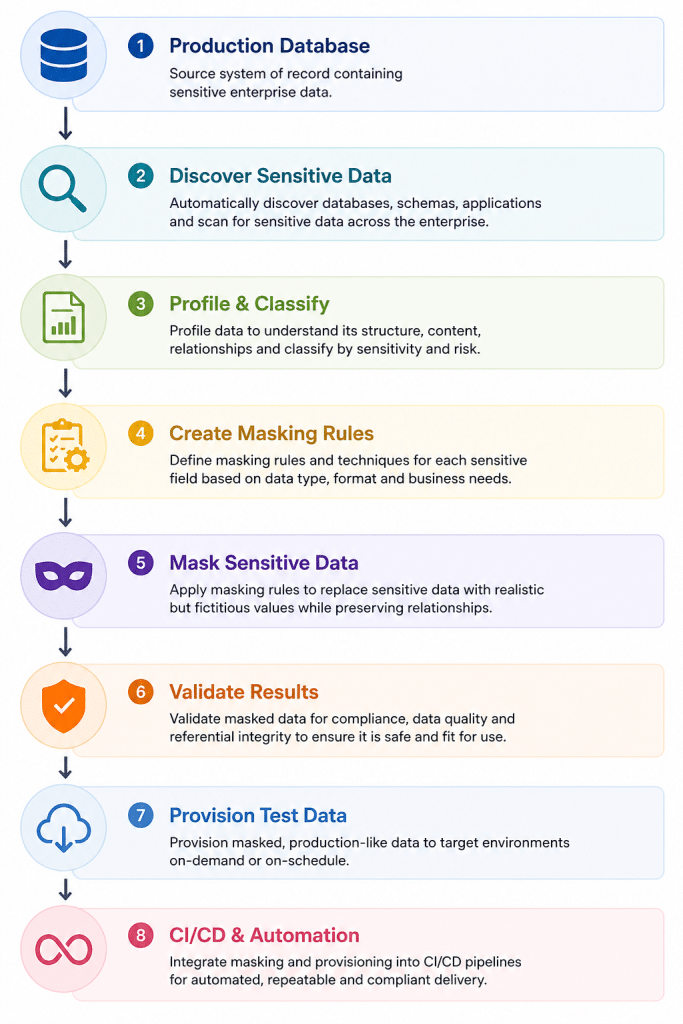
The rest of this article walks through each stage: what it involves, where teams go wrong, and what good looks like.
Step 1: Discover Sensitive Data
You cannot mask what you have not found, and most organizations dramatically underestimate how much sensitive data they hold and where it hides. The obvious columns, NAME, DOB, CARD_NUMBER, are the easy ten percent. The risk lives in the other ninety: free-text notes fields holding pasted customer emails, legacy columns misnamed by a developer a decade ago, staging tables nobody remembers, and JSON blobs stuffed with personal detail.
Discovery at scale means scanning every in-scope schema for the major sensitivity classes:
PII. Direct identifiers (names, addresses, government identifiers, contact details) and quasi-identifiers (dates of birth, postcodes, job titles) that identify individuals in combination.
PHI. Health records, diagnoses, insurance details and treatment histories, the classes regulated under HIPAA and equivalent health privacy regimes.
PCI. Primary account numbers, expiry dates and cardholder data governed by PCI-DSS.
Manual discovery, a spreadsheet and a workshop, is stale before it finishes and blind to anything unexpected. Modern practice is AI-assisted profiling: automated scanners that inspect column names, data patterns and value distributions to flag probable sensitive fields, which a data owner then confirms or rejects. The output is a classification: every field tagged with its sensitivity class and risk level, which becomes the direct input to rule design.
[Screenshot: Enov8 Test Data Manager Profiling Module, showing automated PII discovery results across a schema]
Step 2: Build Masking Rules
With classification in hand, each sensitive field needs a rule. The technique catalogue is well known; the craft is matching the right technique to each field’s format, reuse value and integrity requirements. The question is never “which technique is best” but “what does this field need to survive masking?”
Lookup replacement is the default for identity fields. Names, addresses and phone numbers are swapped for realistic values drawn from lookup libraries. Choose it when the field must remain believable and human-readable, testers should see “Emma Walsh”, not “XXXX”.
Shuffling suits analytical fields where the distribution matters more than the individual value: salaries, order amounts, dates. The set stays statistically true while every row is misaligned from its real owner. Avoid it on small tables, where re-identification by elimination becomes feasible.
Nulling is for fields with sensitivity but no reuse value: free-text comments, attachments, notes. If nothing downstream depends on the content, deleting it is the cheapest and safest rule. Check application logic first, code that expects a populated field will break on null.
Format Preserving Encryption (FPE) fits structured identifiers with validation logic: card numbers with checksums, account numbers with fixed formats. The output passes the same validation as the input. Use it where format compliance is non-negotiable, but treat the keys as production secrets, because FPE is reversible by anyone who holds them.
Deterministic masking is less a technique than a property you apply to other rules: the same input always yields the same output, everywhere. Reserve it for join keys and shared identifiers, and avoid making everything deterministic by default, since consistency trades away a margin of anonymity.
A practical rule of thumb: fewer rule types, applied consistently, beat a bespoke rule per column. Every additional rule variant is another thing to validate, maintain and keep synchronized across systems.
Step 3: Preserve Referential Integrity
This is where most masking projects, and most competitor write-ups, fall down. Databases are not collections of independent columns. They are webs of relationships, and masking that ignores those relationships produces data that is compliant and useless.
Parent and child tables. A customer record in a parent table is referenced by orders, payments and support tickets in child tables. If CUSTOMER_ID 10442 is masked in the parent but the children still point at the old value, every join breaks and the application falls over on first load. Masking rules must cascade through the full dependency graph, primary keys and every foreign key that references them, in one consistent pass.
Foreign keys and implicit relationships. The declared foreign keys are the documented part. Enterprise schemas are full of undeclared relationships: identifiers duplicated into denormalized reporting tables, keys embedded in reference strings, application-level joins the database knows nothing about. Profiling has to surface these, because a masking run that honours only declared constraints will silently orphan the rest.
Cross-database consistency. The same customer exists in the CRM, the billing platform, the data warehouse and the integration layer, often on different database technologies. If “Sarah Chen” becomes “Emma Walsh” in one system and “Olivia Reid” in another, integration testing is dead on arrival. The masking rules, and the value mappings behind them, must execute identically across every platform that shares the data, whether that is PostgreSQL, MySQL, SAP HANA or Snowflake.
Deterministic masking as the mechanism. The way you achieve all of the above is deterministic rules on shared identifiers: the same input value resolves to the same masked value in every table, every database and every masking run. This is precisely why rule design (Step 2) and integrity (Step 3) cannot be separated, the integrity requirement dictates which rules must be deterministic.
Hand-rolled scripts can just about manage integrity inside one database. Across five platforms owned by three teams, it requires a shared rule engine, which is where masking stops being a scripting exercise and becomes a platform decision.
Step 4: Validate the Masking
Never assume the masking worked. Validation is the stage that turns “we ran the job” into “we can prove the environment is compliant”, and it is the stage auditors ask about.
Production smells. Scan the masked environment for indicators that something slipped through: real names surviving in a column the rules missed, valid card numbers passing a Luhn check, email addresses on real corporate domains, government identifier patterns in free text. The concept mirrors code smells, individual findings may be innocent, but each one warrants investigation.
Compliance scanning. Beyond spot checks, run the same discovery profiling from Step 1 against the masked copy. If the profiler still flags sensitive data at material confidence, the rules have a gap. The discovery-mask-rescan loop is the core quality cycle of the whole program.
False positives. Validation tooling will flag things that are not real leaks: lookup-substituted names are, by design, real-looking names. Tuning matters, an alert stream full of false positives trains teams to ignore it, which is worse than no scanning at all. Good practice is to whitelist known lookup libraries and focus scanning on value classes that should never appear post-masking.
Automated validation. Validation must run on every refresh, not once at project launch. Schemas drift, new columns appear, and a rule set that was complete in January is leaky by June. Automated, scheduled validation with results logged as audit evidence is what keeps the program honest over time.
[Screenshot: Enov8 Test Data Manager Validation Module, showing a compliance scan with flagged production smells]
Step 5: Provision Test Data
Masked data sitting in a staging area delivers no value. The final mile is provisioning: getting compliant data into the hands of delivery teams, quickly and repeatably. This is where masking connects to the broader discipline of Test Data Management.
The data factory model. Treat masked datasets as manufactured products: golden masked copies produced on a schedule, catalogued, versioned and ready to dispense. Teams draw from the factory rather than commissioning bespoke extracts, which is how provisioning drops from weeks to minutes.
Bookings. In shared environments, two teams loading conflicting datasets over each other wastes everyone’s sprint. A booking capability lets teams reserve data slices and environments, making contention visible and manageable instead of discovered mid-test.
Database virtualization. Full physical copies of multi-terabyte masked databases are slow to create and expensive to store. Virtualized clones, lightweight, writable copies served from a single masked source image, let every developer and tester have their own environment-sized dataset in minutes, at a fraction of the storage.
Refreshes. Test data ages. Scheduled refreshes re-run the discover-mask-validate pipeline against current production and republish the golden copies, so teams test against data that resembles today’s reality, not last year’s.

Automating Data Masking
Everything above can be run manually. It should not be, because any manual step will eventually be skipped under deadline pressure, and the skipped step is always the one that mattered.
CI/CD integration. Masking and provisioning become pipeline stages: an environment build triggers a masked data load the same way it triggers a code deployment. Compliant data becomes a property of the pipeline, not a request to a team.
DevOps and DataOps. The cultural shift is treating data movement with the same rigour as code movement: version-controlled masking rules, peer-reviewed rule changes, automated testing of the masking itself. DataOps extends the CI/CD mindset to the data supply chain.
Scheduled refreshes. Refresh cadence is set by policy, weekly, per-release, on-demand, and executed automatically, with validation gating each publication. A refresh that fails validation never reaches teams.
Self-service provisioning. The end state: a tester requests a masked dataset from a catalogue and receives it in minutes without raising a ticket. Self-service is what finally removes test data from the critical path of delivery, and it is only safe because discovery, masking and validation are automated behind it.

Common Mistakes
Six failure patterns account for most masking project pain:
Masking too much. Blanket-masking every column, including operational and reference data with no sensitivity, destroys the realism that made production data valuable in the first place. Testers end up with unusable data and quietly source their own, which defeats the entire program.
Masking too little. The mirror image: masking the obvious columns and declaring victory, while quasi-identifiers, embedded keys and derived fields still allow re-identification. Compliance is measured at the dataset level, not the column level.
Forgetting free text. Notes, comments and description fields are where users paste exactly the data your rules protect everywhere else: names, phone numbers, card details, complaints containing full identities. Free text needs either pattern-based scanning and redaction or nulling, never a pass.
Breaking referential integrity. Masking keys without cascading the change, or missing undeclared relationships, produces environments that fail on first login. Worse, teams then “fix” it by requesting unmasked data.
Inconsistent rules across systems. Different teams masking the same shared entity with different rules guarantees that end-to-end and integration testing cannot work. One rule set, one engine, every platform.
Slow refreshes. If a masked refresh takes three weeks, teams will test against stale data or bypass the process. Speed is a compliance control: the faster the compliant path, the less incentive there is to route around it.
Enterprise Architecture
Putting it all together, the reference architecture for enterprise masking looks like this:
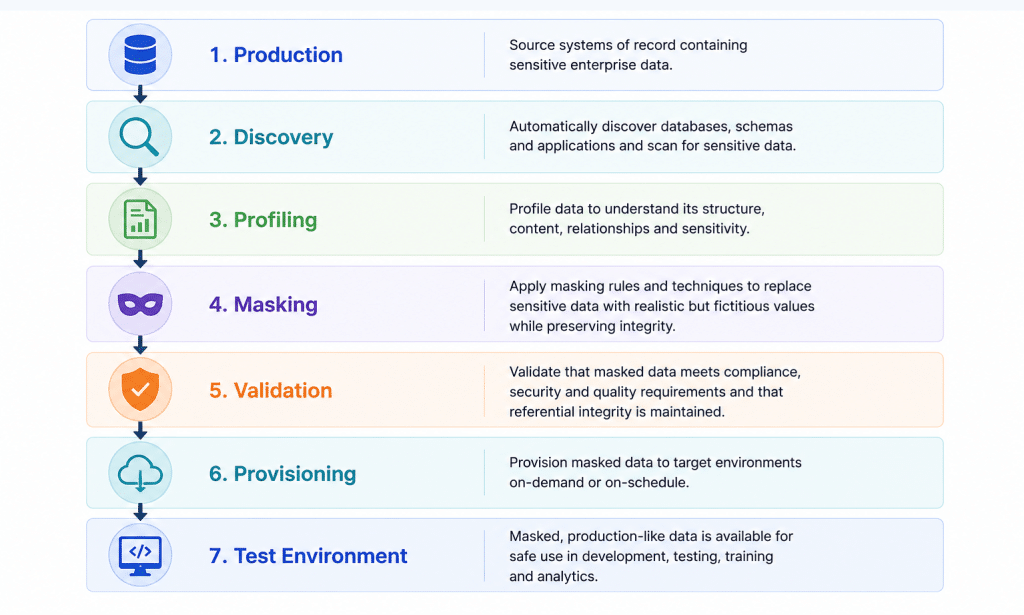
Two properties distinguish an architecture from a collection of scripts. First, each stage feeds the next: discovery output drives profiling, profiling drives rule generation, validation gates provisioning. Second, the whole flow is repeatable on demand, which is what allows it to run inside CI/CD rather than as a quarterly project. The same architecture holds whether the estate is on-premise relational, AWS-hosted, or a modern cloud data platform.
How Enov8 Automates the Process
Each stage above maps directly to a module of Enov8 Test Data Manager, which is the point: the platform automates the workflow rather than offering masking as an isolated function.
Profiling and discovery. The Profiling Module uses AI-assisted scanning to discover and classify PII, PHI and PCI across schemas and platforms, producing the classification that drives everything downstream, and replacing the workshop-and-spreadsheet approach that stales on contact with reality.
Masking. The Masking Module generates consistent, deterministic rules directly from profiling output and executes them across heterogeneous database platforms, which is how cross-system referential integrity is maintained without per-database script maintenance.
Validation. The Data Validation module runs automated compliance scans against masked environments, hunting production smells and producing the audit evidence that regulators and security teams ask for.
Data factory and provisioning. Test data operations, golden copy management, bookings, scheduled refreshes and self-service requests, turn masked data into an on-demand service for delivery teams.
Database virtualization. Enov8 vME provisions masked databases as lightweight virtual clones, cutting environment data delivery from days to minutes and removing the storage cost of full physical copies.
If you are earlier in the journey and still comparing approaches, our roundup of data masking solutions covers the wider market. And if you landed here without the fundamentals, the pillar guide, What is Data Masking?, covers definitions, types and the masking-versus-encryption question in depth.

This post was written by the Enov8 team. Enov8 is the unified platform for modern IT delivery, connecting applications, environments, data and releases from strategic planning to automated execution.