Self-Healing Applications
NOV, 2022
by Sylvia Froncza
Original March 2019
Author Sylvia Froncza
This post was written by Sylvia Fronczak. Sylvia is a software developer that has worked in various industries with various software methodologies. She’s currently focused on design practices that the whole team can own, understand, and evolve over time.
An IT and Test Environment Perspective
Traditionally, test environments have been difficult to manage. For one, data exists in unpredictable or unknown states. Additionally, various applications and services contain unknown versions or test code that may skew testing results. And then to top it all off, the infrastructure and configuration of each environment may be different.
But why is that a problem? Well, although testing and test management play a crucial role in delivering software, they often get less attention than the software development process or production support. And without efficient, repeatable, and properly configured test environments, we can greatly delay the delivery of new features or allow devastating bugs into production.
Fortunately, a solution exists for your test environment management (TEM) woes. Because with self-healing applications and environments, you gain access to standardized, repeatable, and automated processes for managing your environments.
Enov8 IT & Test Environment Manager
*Innovate with Enov8
Streamlining delivery through effective transparency & control of your IT & Test Environments.
In this post, we’re going to discuss self-healing applications, separate the hype from reality, and get you started on the self-healing journey. And we’ll be considering all of this from the perspective of IT and TEM.

What Is a Self-Healing Application?
A self-healing application, as the name suggests, is an application that heals itself—in other words, the app itself, when suffering from a problem, it’s capable of fixing it automatically. By doing so, the application can keep working instead of crashing, ensuring higher availability and a better user experience.
How Does Self-Healing Code Work?
Does the definition above sound too good to be true? Well, but it’s not. Self-healing code can work in a variety of ways, but the main principle is always the same: to have some form of fallback or plan b to use when the intended course of action doesn’t work. As you’ll soon see, this can be as simple as using retry logic to make a new attempt when the call to a dependency fails.
The important part to notice is this: though the execution of the self-healing process is (mostly) automatic, putting the process in place is the result of human work and creativity. At the end of the day, there’s no magic involved.
Despite how nice it is to have more availability, that’s not the whole story. Let’s now cover some real-world challenges that are solvable via self-healing applications and environments.
Why Do We Need Self-Healing Apps and Environments?
Since you’re on Enov8’s blog, you may already be familiar with some of the challenges that exist with test environment management. But let’s briefly review some of them.
Limited Number of Test Environments
First, even fairly mature companies have a limited number of test environments. This might not seem like a big deal, but many of us have felt the crunch when multiple initiatives are tested at once. Initiative “A” locks down the system integration environment, while initiative “B” requires kicking everyone out of the end-to-end environment. Then, load testing requires the use of pre-production, while smaller projects and work streams scramble to find time slots for their own testing.
Unknown State of Environments
Later, once the environments are free for testing again, no one knows the current state of anything: data, versions, configuration, infrastructure, or patches. And it’s a manual process to get things back to where they need to be.
Not Able to Replicate Production
Additionally, test environments do not typically have as many resources available as the full-blown production environment. This is usually a cost-cutting measure, but it often makes load testing difficult. Therefore, we often have to extrapolate how the production environment will react under load. If we could easily scale our test environment up or down, we might have better data around load testing.
Painful Provisioning
Finally, with the increasingly distributed systems we rely on, it’s becoming more and more difficult to manually provision and later manage new test environments. And because many of the processes are manual, finding defects related to infrastructure setup and configuration becomes increasingly difficult. For example, if patches roll out manually to fix infrastructure bugs, QA personnel can’t always see easily what patches have been rolled out where.
Now let’s look at what self-healing applications and environments are and how they can help.
What’s Self-Healing?
Self-healing implies the ability of applications, systems, or environments to detect and fix problems automatically. As we all know, perfect systems don’t exist. There are always bugs, limitations, and scaling issues. And the more we try to tighten everything up, the more brittle the application becomes.
So what do we do? Embrace the possibility of failure. And automate systems to fix issues with minimal intervention.
Now, please note I said minimal intervention. Though self-healing purports to eliminate the need for human intervention entirely, that’s not quite true. It reduces the need, but it doesn’t completely eliminate it. We’ll talk more about that later in this post.
But first, let’s examine the two types of self-healing processes.
Reactive vs. Preventive
There are two types of automated healing we’ll discuss today: reactive and preventive.
Reactive healing occurs in response to an error condition. For instance, if an application is down or not responding to external calls, we can react and automatically restart or redeploy the application. Or, within an application, reactive healing can include automated retry logic when calling external dependencies.
Preventive healing, in contrast, monitors trends and acts upon the application or system based on that trend. For example, if memory or CPU usage climb at an unacceptable rate, we might scale the application vertically to increase available memory or CPU. Alternatively, if our metrics trend upward due to too much load, we can scale the application horizontally by adding additional instances before failure.
Thorough self-healing necessitates both types of measures. However, when getting started it’s easier to add reactive healing. That’s because it’s typically easier to detect a complete failure or error condition than it is to detect a trend. And the number of possible fixes is typically smaller for reactive healing, too.
Self-Healing Applications
OK, so then what are self-healing applications? Well, they’re applications that either reactively or preventively correct or heal themselves internally. Instead of just logging an error, the application takes steps to either correct or avoid the error.
For example, if calling a dependency fails, the application may contain automatic retry logic. Alternatively, the application could also go to a secondary source for the call. One common use of this involves payment processing. If calls to your primary payment processor fail after a few attempts, the application will then call a secondary payment processor.
Self-Healing Systems and Test Environments
Beyond an application, we encounter the system that contains it and possibly other applications that work together. Here, when we talk about self-healing systems or environments, we should consider generalized healing processes that can be applied regardless of what types of applications make up the core.
For example, if an application in an environment is unreachable, then redeploying or restarting the application can react to the down state. Additionally, if latency or other metrics show service is degrading, scaling the number of instances can help. All these corrective measures should be generic enough that they can be automated. They apply to many different application types.
Self-healing at an environment level incidentally provides self-managed environments as well. If scripts exist that scale or deploy applications in case of error, they can also automate provisioning environments for specialized and self-service test environments.
Principles of Self Healing
Let’s discuss some general principles that can guide you when implementing a self-healing system.
")
Resource Protection
Resource protection here means designing your systems in such a way that doesn’t overtax failing systems. If a call to a dependency fails, retry a few times, but not too much, as that might put too much pressure on a failing service. Instead, fall back to a backup call when possible. Alternatively, a pattern like the circuit breaker can be used to preemptively avoid the call to service when that’s likely to fail.
User’s Best Interest
Always have the end user’s best interest in mind. For example, when dealing with financial transactions, design your resilience logic so that clients aren’t billed twice. In that spirit, it’s better to fail to process the payment—the system can make an attempt again later—than to charge a client unnecessarily.
User Experience
Always keep the user experience in mind as well. If a call to a dependency fails irrevocably, and that dependency isn’t an indispensable one, it’s possible to degrade gracefully, offering reduced functionality to the user instead of crashing.
Comprehensive Testing
Testing is essential for achieving self-healing systems. And the testing of the sad path is particularly important since, oftentimes, teams will only concentrate on the happy path. By testing with fault injection, it’s possible to validate the system’s resilience, making it less likely that severe problems will even make it to production.
Challenges of Implementing Self Healing
Getting a self-healing application or environment in place is no easy feat. Here are some challenges you may face:
- Fragmented IT, leading to the difficulty in integrating systems and processes when diagnosing issues
- Lack of CI/CD maturity, which makes it harder to implement automatic rollback into a pipeline
- Resistance to automating processes due to a culture of manual troubleshooting, which can lead to job security concerns.
Two of the three challenges above are technical, and they are addressed in the Groundwork section you’ll soon see. Basically, put in work into observability, testing and improving your pipeline. The third challenge, though, is cultural, which means it must be addressed by each organization.
Getting Started
You can’t get to fully self-healing applications and environments overnight. And you’ll have to lay some solid groundwork first. Here’s how.
Groundwork
First, you’ll need to make some upfront investment in the following:
- Infrastructure as code. Infrastructure as code makes provisioning servers repeatable and automated using tools like Terraform or Chef. This will let you spin up and tear down test environments with ease.
- Automated tests. These tests shouldn’t just be tests that run as part of your integration pipeline. You’ll also want long-running automated tests that continually drive traffic to your services in your test environments. These tests will spot regression issues and degradation in performance.
- Logging. Next, logging will give your team the ability to determine root cause faster. It will also help identify the aspects of your environment to which you can apply self-healing processes.
- Monitoring and alerting. Finally, monitoring will let you see trends over time and alert you to issues that can’t be resolved through self-healing processes.
Prioritization
Once you have the basics in place, take stock of your environments and the pain points your QA team experiences. Then, draw a graph like the one shown below to chart the potential frustration and time commitment of self-healing automation against how easy automation would be. Once you’re done plotting your automation opportunities, start at the top right of the graph to implement the easiest automation process that offers the most benefit.
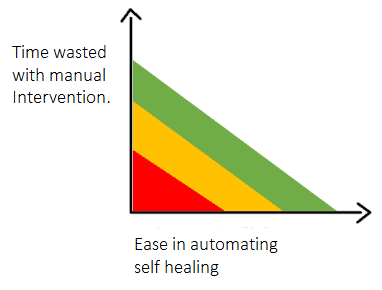
Another way to start involves identifying symptoms that require manual intervention as well as the possible automation that would resolve them. Let’s look at a few examples:
Symptom: Service is unreachable.
Automation: Restart or redeploy to a known good state.
Symptom: Increase in errors reported.
Automation: Alert appropriate parties; redeploy to a known good version.
Symptom: Latency increases under load.
Automation: Scale application and report result.
However you decide which self-healing automation to add, it will require tweaking and monitoring over time to make sure you’re not masking issues with simple hacks.
Does This Mean We Don’t Need People?
Before we conclude, let’s talk about one misconception of self-healing applications. Often a purported benefit includes completely eliminating manual intervention. But does that mean we don’t need people anymore?
Of course not. Because we still have to investigate why the applications or environments need to self-heal. So for every unique self-healing episode, we should look at the root cause. And we should consider what changes can be made to reduce the need for self-healing in the future.
What self-healing applications and environments can do is reduce busy work. This, in turn, reduces the burden on support staff who must react immediately to every outage or problem. That frees them up to make the system more reliable as a whole.
So, in addition to healing systems, take care to also put in proper monitoring and logging. Then the people involved in root cause analysis will have all the tools to investigate and won’t be bothered by repeating manual steps to get systems back online.
All of this combines to make QA and development teams happier and more productive.
Healing Your Test Environments
Hopefully you’ve now gained a better idea of what self-healing can do for your organization. By looking at reactive and preventive manual actions, you can build automated processes that will improve efficiency and time to resolution for many failures. And with proper monitoring tools, you’ll feel confident that your processes work.
Relevant Articles

9 Planview Alternatives Compared: Features, Pros, and Cons
Planview is a popular enterprise project portfolio management (PPM) platform, but it isn't the right fit for every organization. Some teams need a simpler platform, lower costs, stronger Agile support, or better integrations with the tools they already use....

Vector Store Masking Software: Why It Matters for Enterprise AI
Artificial intelligence is helping organizations search, retrieve, and use information in entirely new ways. Technologies like retrieval-augmented generation (RAG), enterprise search, and AI assistants all rely on vector stores to quickly find the most relevant...

SAP HANA Data Masking: A Complete Guide
Using production data makes development and testing much more effective, but it also introduces a challenge: How do you give teams realistic data without exposing sensitive information? SAP HANA data masking solves that problem. In this guide, you'll learn what it is,...

Databricks Data Masking: Best Practices, Techniques, and Tools
Organizations use Databricks to build data pipelines, power analytics, and develop machine learning and AI solutions on a unified lakehouse platform. Much of the data stored in Delta Lake tables includes personally identifiable information (PII), financial records,...
Why Generate Everything? Generate Only What’s Missing
There's a quiet assumption baked into a lot of synthetic data strategies: if you need test data, you generate it. All of it, from scratch, every time. It feels like the modern, AI-powered answer to test data. But it's often the slow, expensive answer to a problem...

MongoDB Data Masking: Benefits, Challenges, and Best Practices
MongoDB powers many modern applications, from customer-facing platforms to analytics systems and cloud-native services. As organizations store increasing amounts of customer, employee, financial, and operational data within MongoDB, they must protect that information...