Sand Castles and DevOps at Scale
JUNE, 2022
by Niall Crawford & Carlos “Kami” Maldonado.
Modified by Eric Goebelbecker.
DevOps at scale is what we call the process of implementing DevOps culture at big, structured companies. Although the DevOps term was back in 2009, most organizations still haven’t completely implemented the practice.
DevOps used to be most popular at start-ups. After all, it’s easy to introduce processes that break the rules when you had no rules to begin with. But this has left large corporations and bureaucratic organizations to watch DevOps from the sidelines.
Now, things have finally changed. If we check the numbers from the 2021 edition of Accelerate: State of DevOps Report, it’s evident that big players in the industry are actively implementing DevOps practices. Could you do this at your organization? When applying DevOps at scale, you’ll face a collection of hurdles. Let’s look at how to overcome some of them.
A Bit of History
DevOps first appeared back in 2008 at an agile conference in Toronto. In a nutshell (and with the help of Wikipedia), we can define it as a software engineering culture and practice that aims at unifying software development (Dev) and software operation (Ops). DevOps intends to reduce the time between committing a change to a system and the change being placed into normal production while ensuring high quality.
That’s the theory, but your mileage may vary. The success of DevOps depends on the quality of individuals and how well the team works together. The biggest challenge is that few changes touch only one system. It’s usually the opposite; a change impacts many systems, processes & services.
In today’s complex IT environments, few systems or components are islands. And that’s where the issue with DevOps lies; it encourages a culture of “System” or “Team Thinking.” However, effective DevOps at scale requires us to think at a broader “Enterprise” level.

An Analogy: DevOps & DevOps at Scale
It’s a little bit like comparing the building of Sand Castles on a Beach to Town Planning. Yes, it’s fun, and you might build a damn good sandcastle, but, unfortunately, some of your sister teams will fall short of the mark, and ultimately the whole task of integrating is going to slow down, and the so-called “Release Train” will grind to a halt.
Delivering DevOps at Scale
Organizations cannot expect DevOps teams that are naturally focused on discrete systems or atomic tasks to manage and deliver a solution at scale. Not unless there’s some form of enterprise harness that ensures all the moving parts are effectively orchestrated. DevOps is more than simple Code, Build, Test, Package, Release, Configure & Monitor. DevOps at Scale is about resolving the classical cross-system orchestration challenges experienced today and providing an approach, preferably a complimentary & non-obtrusive approach, that overarches existing DevOps methods and ensure the release train wheels are greased and your delivery is streamlined.
Five Practices
As a way of preparing for a DevOps at scale capability, here are five practices to promote.
- Understand what your End-to-End Environments look like.
Look beyond your systems & model the End to End IT & Test Environments they live in. Understand them intrinsically i.e. map your components, dependencies, interfaces, business relationships, processes, and supporting operations.
- Shift your release / operational planning & coordination left
Avoid the ongoing issues around System not being fit for purpose and/or contention. Capture project & portfolio demand as early as possible and establish effective notification & transparency methods to ensure readiness and awareness.

- Don’t neglect the data
How often do you see the CICD solutions fail as nobody bothered about the data? In addition to streamlining Application & Infrastructure tasks, invest in data. Automate key data tasks like ETL (Extract, Transform & Load) and/or Fabrication and ensure the automation methods are “cross system aware”, thus ensuring E2E integrity.
- Orchestrate enterprise release activity
Avoid common “release issues”, “deployment delays” and “rollbacks” by adopting an “Enterprise Release Management” (ERM) strategy. A strategy that promotes prioritization of change, alignment of cross-system release activities, and promotes consistent and repeatable operations.
- Promote higher levels of “Enterprise Intelligence”
System metrics are fine although off little use to executive decision makers or your CIO. Start capturing & reporting on “Enterprise Metrics” i.e. metrics that allow the senior executives to see the “forest from the trees”. Examples may include Team Performance, Compliance, Automation & Innovation
Solutioning
Enov8 provides a complete platform for addressing organizations’ DevOps at scale requirements. Providing advanced “out of the box” IT & Test Environment Management and Release Management capabilities, the enov8 platform uplifts enterprise transparency, command, and ultimately control.
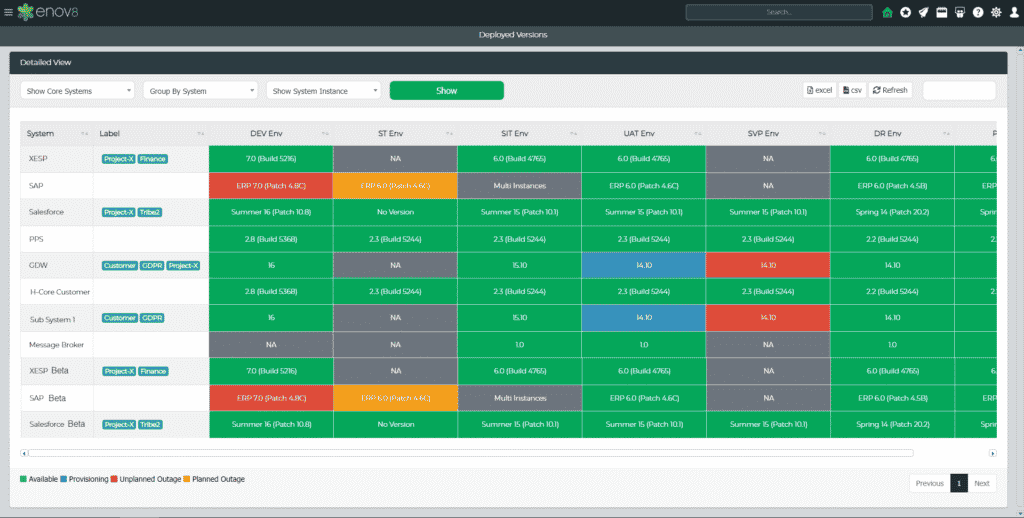
Innovate With Enov8
If you are interested in learning more about IT & Test Environment Management and IT Release Management, contact us about EcoSystem.
Enov8 EcoSystem is the worlds leading IT Enterprise Intelligence platform.
EcoSystem is a fully configurable and easily integratable solution that comes with out of the box “enterprise management” functions that support IT & Test Environment Management, Release Management, Data Management, IT Operations Management, Configuration Management & Service Management.
Post Author
This post was originally written by Niall Crawford & Carlos “Kami” Maldonado. Modified for re-publication by Eric Goebelbecker.
Niall Crawford Niall is the Co-Founder and CIO of Enov8. He has 25 years of experience working across the IT industry from Software Engineering, Architecture, IT & Test Environment Management and Executive Leadership. Niall has worked with, and advised, many global organizations covering verticals like Banking, Defence, Telecom and Information Technology Services.
Carlos “Kami” Maldonado Kami is an engineer helping his company transition to DevOps. He specializes in Linux automation, and he’s experienced in all layers of infrastructure, from the application layer down to the cable. He’s part of a team migrating a monolithic app from static VMs to on-premises Kubernetes deployments.
Eric Goebelbecker Eric has worked in the financial markets in New York City for 25 years, developing infrastructure for market data and financial information exchange (FIX) protocol networks. He loves to talk about what makes teams effective (or not so effective!).
Relevant Articles

7 Synthetic Data Generation Tools for Dev & Testing
In software development and testing, having access to high-quality, realistic data is crucial. But real production data is often sensitive, regulated, or simply unavailable for testing purposes. Synthetic data generation tools provide a powerful alternative, enabling...

The SAFe Hierarchy and Levels, Explained in Depth
The Scaled Agile Framework (SAFe) is a comprehensive set of principles and practices designed to help organizations adopt agile methods on an enterprise level. It provides a set of guidelines and best practices that enable large-scale product development with agility....

DORA Compliance – Why Data Resilience is the New Digital Battlefield
How Enov8 Helps Financial Institutions Align with the EU's Digital Operational Resilience Act Executive Introduction As of January 2025, the EU's Digital Operational Resilience Act (DORA) has become legally binding for financial institutions operating across the...
Data Fabric vs Data Mesh: Understanding the Differences
When evaluating modern data architecture strategies, two terms often come up: data fabric and data mesh. Both promise to help enterprises manage complex data environments more effectively, but they approach the problem in fundamentally different ways. So what’s...

What Is Release Management in ITIL? Guide and Best Practices
Managing enterprise software production at scale is no easy task. This is especially true in today’s complex and distributed environment where teams are spread out across multiple geographical areas. To maintain control over so many moving parts, IT leaders need to...

Test Environment: What It Is and Why You Need It
Software development is a complex process that requires meticulous attention to detail to ensure that the final product is reliable and of high quality. One of the most critical aspects of this process is testing, and having a dedicated test environment is essential...