
Generating the right test data is a critical challenge for QA and development teams.
Without realistic, compliant, and well-managed data, testing can yield misleading results or miss crucial bugs. You don’t want your customer sign-up to fail because it never occurred to you (or your test data generation scheme) that people might have characters in their names that weren’t letters.
Synthetic test data generation tools address these challenges by creating high-quality, customizable datasets that accelerate testing cycles while maintaining data privacy.
This article explores what to consider when choosing a test data generation tool and reviews seven leading options to help you find the best fit for your team’s needs.
Why Generating the Right Test Data Is Critical
Test data fuels the software testing process, allowing teams to validate functionality, performance, and security across a variety of scenarios. However, relying on real production data is often impossible due to privacy concerns and regulatory constraints.
Synthetic data generation tools help teams overcome these barriers by producing artificial datasets that mimic real-world data patterns without exposing sensitive information.
Well-generated test data not only improves test coverage and accuracy but also supports compliance with regulations like GDPR, HIPAA, and CCPA. Moreover, it enables continuous testing in DevOps pipelines, reducing bottlenecks and helping teams deliver high-quality software faster.
What to Consider When Choosing a Test Data Generation Tool
When selecting a test data generation tool, several key factors come into play. First, the balance between realism and randomness matters—while data should reflect the characteristics of real datasets, some randomness ensures coverage of edge cases and unexpected inputs.
Privacy and compliance capabilities are paramount. Tools must offer masking, anonymization, or synthetic data generation methods that meet your organization’s regulatory requirements. Automation and integration capabilities are also critical for embedding test data generation seamlessly into CI/CD pipelines, minimizing manual effort and errors.

7 Test Data Generation Tools for QA and Dev Teams
1. Tonic.ai
Tonic.ai excels at generating high-fidelity synthetic data that preserves the statistical properties and relationships of your real datasets. It supports various data types and integrates easily with existing development workflows, making it a favorite for teams prioritizing data realism and privacy compliance.
Pros: High data fidelity, strong privacy features, developer-friendly.
Limitations: Pricing may be steep for smaller organizations.
2. Mockaroo
Mockaroo offers a user-friendly, web-based platform to generate realistic sample data quickly. It’s ideal for smaller-scale projects or teams needing customizable data schemas without complex setup.
Pros: Easy to use, customizable schemas, free tier available.
Limitations: Limited enterprise-grade features and governance.
3. GenRocket
GenRocket provides a scalable synthetic data generation platform focused on automated data creation for complex test scenarios. It supports a wide variety of data types and integrates well with CI/CD pipelines.
Pros: Scalable, automation-friendly, flexible scenario creation.
Limitations: Learning curve for advanced configurations.
4. IBM InfoSphere Optim
IBM InfoSphere Optim offers comprehensive test data management, including synthetic data generation, masking, and governance. It suits enterprises needing robust compliance and integration capabilities.
Pros: Strong governance, enterprise integration, compliance-focused.
Limitations: Complexity and cost may deter smaller teams.
5. DATPROF
DATPROF specializes in privacy-compliant synthetic data generation with automation features designed to reduce manual testing overhead. It supports real-time data masking and integrates well into DevOps workflows.
Pros: Privacy-centric, automation capabilities, good integration.
Limitations: Smaller market presence than larger incumbents.
6. Test Data Automation by Curiosity Software
Curiosity Software’s Test Data Automation focuses on accelerating test data creation through intelligent automation. It helps reduce test cycle times while ensuring data quality and compliance.
Pros: Intelligent automation, reduces cycle times, compliance support.
Limitations: Niche solution, less widely known.
7. Enov8 TDM – Intelligent Test Data Generation via DataFactory
Enov8 Test Data Management (TDM), powered by the DataFactory engine, introduces a modern, efficient approach to synthetic test data generation—focused on generating only what’s missing.
Rather than creating redundant datasets, Enov8 promotes data reuse and mining first, identifying available records across connected environments. When gaps are found, such as missing boundary values, negative cases, or rare data combinations, DataFactory steps in to generate only the 1% you actually need.
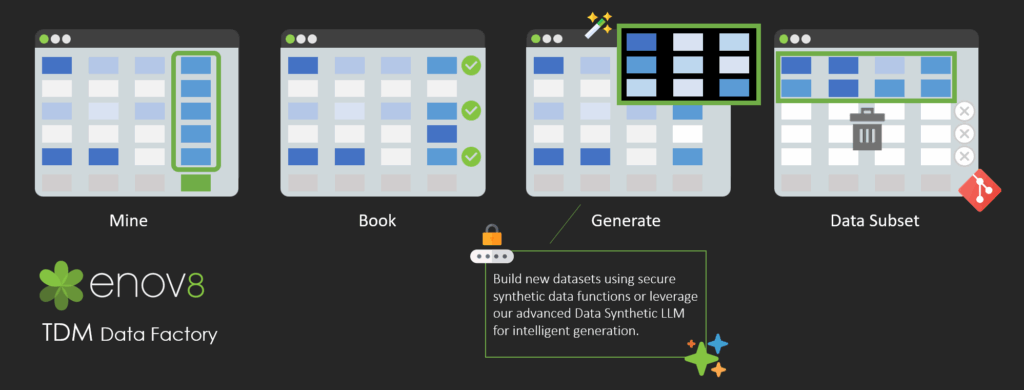
Generation routines are powered by either:
(a) Out-of-the-box secure Synthetic functions, or
(b) Local LLMs, enabling context-aware, intelligent data generation while maintaining data sovereignty and security.
This ensures faster cycles, smaller datasets, and more relevant test scenarios—with full auditability and compliance at scale.
Key Differentiators:
✅ “Find First, Generate Last”: Data mining and reuse reduce effort and duplication
✅ AI-Ready: Local LLMs for smarter, context-driven generation
✅ Secure & Compliant: Built-in masking, access control, and audit trails
✅ Orchestrated: Integrates seamlessly into CI/CD pipelines & environment provisioning workflows
✅ Governed at Scale: Enterprise-wide visibility and policy enforcement across test data activities
Pros: Efficient, AI-augmented, governance-centric, reduces overgeneration
Limitations: Requires source data connection for full data mining benefits
Making Test Data Generation Work at Scale
Successfully scaling synthetic test data generation is a multifaceted challenge that extends far beyond simply selecting the right tool. Organizations must think strategically about how synthetic data fits into their entire software delivery lifecycle.
This means embedding test data generation seamlessly into automated CI/CD pipelines so that data is always fresh, relevant, and aligned with the latest code changes. Automation reduces manual bottlenecks and the risk of errors, allowing teams to test more frequently and with greater confidence.

At scale, governance becomes an indispensable pillar of test data management. Without strong governance frameworks, synthetic data can become inconsistent or fragmented as multiple teams generate and use datasets independently. Enforcing policies around data privacy, access control, and usage ensures that synthetic data remains compliant and trustworthy across all environments.
Equally important is continuous validation — teams need to routinely check that the synthetic data accurately reflects the statistical and structural properties required for realistic testing.
This ongoing quality assurance prevents drift and maintains the integrity of testing outcomes, ultimately reducing costly defects and rework.
Scaling synthetic data efforts also requires a cultural shift within organizations. Collaboration between QA, development, security, and compliance teams is vital to align objectives, share insights, and resolve challenges. Investing in centralized platforms or orchestration tools can facilitate this collaboration, providing visibility and control over synthetic data assets.
Only by treating test data generation as a holistic, governed process can enterprises fully unlock its benefits at scale.
Common Pitfalls and How to Avoid Them
1. Overreliance on Production Data
One of the most frequent mistakes organizations make is relying too heavily on snapshots of production data for testing. While it may seem convenient, this practice introduces serious privacy risks and can violate data protection regulations such as GDPR and HIPAA.
Instead, teams should leverage synthetic data generation tools that create anonymized or masked datasets, preserving data utility without exposing sensitive information.
2. Poor Integration with Existing Workflows
Using synthetic data tools that do not integrate well with your current CI/CD pipelines, test management systems, or development workflows can lead to fragmentation and inefficiency. Without seamless automation, manual steps increase the risk of errors and slow down testing cycles.
Selecting tools with strong API support and integration capabilities ensures that test data generation becomes a natural part of your software delivery process.
3. Neglecting Governance and Compliance
Governance often gets overlooked in synthetic data initiatives, yet it is essential to maintain data quality and regulatory compliance. Without clear policies, role-based access controls, and audit trails, organizations struggle to demonstrate compliance and manage risk.
Embedding governance early ensures consistent enforcement of masking, anonymization, and data usage policies.
4. Siloed Teams and Lack of Collaboration
Synthetic data generation efforts can falter if development, QA, and compliance teams operate in isolation. Misaligned goals, duplicated efforts, and communication gaps lead to inconsistent data and unreliable test results. Encouraging cross-team collaboration and shared responsibility for test data workflows is crucial for success.
5. Ignoring Continuous Validation and Quality Checks
Synthetic data isn’t a “set it and forget it” solution. Without ongoing validation, synthetic datasets can drift away from the statistical properties or scenarios they are meant to simulate, reducing test effectiveness.
Regularly monitoring and tuning your synthetic data generation processes ensures that your test data remains accurate and relevant.
Why Governance Matters When Scaling Test Data
Governance is the backbone of any successful enterprise synthetic test data strategy, particularly as organizations scale their testing activities. When synthetic data is generated, shared, and consumed across multiple teams and environments, governance ensures that this process happens securely, consistently, and in compliance with regulatory requirements.
It provides a framework of policies and controls that govern who can access or modify synthetic datasets, ensuring sensitive information is protected and usage is appropriate.
Beyond security, governance delivers auditability—detailed logs and traceability that document the lifecycle of synthetic data. This visibility is critical for regulatory audits, enabling organizations to demonstrate how test data complies with privacy laws like GDPR, HIPAA, or CCPA. It also supports internal quality assurance by making it easier to identify the origins of data issues or anomalies.
Governance further enforces data versioning and policy adherence, which are vital when different teams are working with synthetic data for varying purposes. Without such controls, synthetic data can become inconsistent or outdated, undermining testing reliability.
By embedding governance deeply into the test data generation and management lifecycle, enterprises not only reduce risk but also increase confidence that testing results are valid and reproducible across complex environments.
Learn How Enov8 Supports Test Data Strategy at the Enterprise Level
Enov8’s TDM platform offers comprehensive test data management and governance designed to meet enterprise demands. With built-in compliance features and workflow orchestration, it helps organizations reduce risk and accelerate delivery. Download the Bloor InBrief Report on Enov8 to read more.

