
Testing is an essential part of maintaining a healthy Guidewire environment. But because Guidewire applications handle large volumes of personally identifiable information (PII), simply copying production data for testing or training isn’t an option. This is where data masking comes in.
In this introductory guide, we’ll unpack what Guidewire data masking means, why it’s critical for insurers, how it works, and how to implement it effectively as part of your broader test data management (TDM) and environment management strategy.
What Is Guidewire Data Masking?
Guidewire is a suite of insurance applications that includes PolicyCenter, BillingCenter, and ClaimCenter. These systems manage customer, policy, and claims data — nearly all of which is sensitive.
Data masking, in this context, means the process of obfuscating that sensitive data when it’s copied from production into non-production environments like development, QA, or user acceptance testing. The goal is to make the data realistic enough for testing while ensuring that no personally identifiable or financial information remains exposed.
For example, a real policyholder name such as “Maria Torres” might be replaced with “Pat Johnson,” and a credit card number with a randomly generated value. The masked data still behaves like real production data in Guidewire workflows, but it can’t be traced back to an actual customer.
Why Data Masking Matters in Guidewire Environments
Insurance organizations are prime targets for cyberattacks, largely because of the depth of personal and financial data they handle. Even when test systems aren’t exposed to the public, they often run on networks or platforms with less stringent security controls than production.
Using unmasked production data in these environments creates compliance and reputational risks. Regulatory frameworks like GDPR, CCPA, and HIPAA all require that personally identifiable information be protected across its entire lifecycle — including in test or staging systems.
Effective data masking reduces this risk by ensuring that data used outside production can’t cause a breach or regulatory violation. Beyond compliance, masking also supports safer collaboration, faster audit cycles, and more efficient testing by allowing teams to work with data that’s consistent, safe, and representative.

How Data Masking Works in Guidewire Applications
Guidewire applications rely on a central relational database that stores customer, policy, billing, and claims information. Because this data contains extensive PII, the database becomes the primary target for masking before any copy is used in non-production environments.
+ Static Data Masking (Most Common for Guidewire)
Static masking replaces sensitive values before the data is moved into SIT, UAT, or performance environments. It is the standard approach used by Enov8 because it ensures data is safe the moment it leaves production while still maintaining the structure and usefulness of the dataset.
+ Dynamic Data Masking (Less Common)
Dynamic masking applies rules at query time rather than altering the stored data. While useful in analytics or support scenarios, it is rarely used in Guidewire programs due to its complexity and performance overheads.
Two Approaches to Masking Guidewire Data with Enov8
Based on hosting model, Guidewire deployments fall into two main categories. Each requires a different technical approach to masking.
1. Guidewire Cloud (SaaS): Data Masking via Extract–Mask–Load Pipelines
When Guidewire is delivered as a SaaS platform, direct access to the production or non-production databases is not permitted. Customers cannot export data directly, cannot run SQL against the cloud databases, and cannot self-service environment refreshes. Instead, Guidewire Cloud provides a controlled and auditable pathway for delivering production-like test data into lower environments.
Typical workflow:
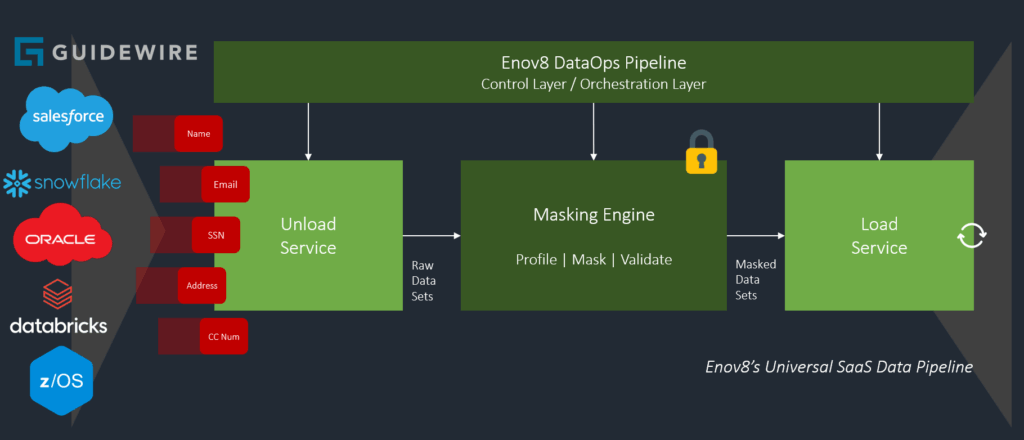
The approved workflow for insurers is:
1. Guidewire Generates a Production Snapshot (Guidewire Responsibility)
To initiate a refresh cycle, Guidewire Cloud Operations creates a Production Snapshot—a point-in-time export of the production database. This snapshot contains the full data set, including PII, and is delivered securely to the customer’s cloud tenancy. Importantly, customers never access the live Guidewire Cloud production database; they only receive the sanctioned export.
2. Customer Masks the Snapshot in Their Own Environment (Customer Responsibility)
Once received, the customer performs masking within their own infrastructure using their masking tools and governance frameworks. This is where Enov8’s platform or similar TDM solutions can apply consistent, format-preserving, referentially-intact masking across the entire Guidewire dataset. Masking must be completed before the data is returned to Guidewire, as unmasked PII cannot enter any non-production Guidewire Cloud environment.
3. Customer Returns the Masked Dataset to Guidewire (Shared Responsibility)
After masking, the customer provides the masked snapshot back to Guidewire Cloud Operations through the agreed secure channel. Guidewire validates that the dataset is masked appropriately and matches the required version and schema.
4. Guidewire Loads the Masked Dataset into SIT/UAT/Performance (Guidewire Responsibility)
Guidewire Cloud Operations performs the full environment refresh: replacing the database, rebuilding indexes, validating services, restarting application nodes, and completing smoke tests. Only after successful validation is the refreshed environment handed back to the customer for testing.
Why This Workflow Matters
This model provides the insurer with realistic, production-scale test data without exposing raw PII and without breaching cloud security boundaries. Masking happens entirely outside the Guidewire Cloud, while all extract and load activities are handled by Guidewire to maintain platform integrity.
2. On-Premise or Self-Hosted Guidewire: Direct Masking of Backend Databases
In an on-premise or self-hosted Guidewire deployment, Enov8 connects directly to the underlying Guidewire databases, enabling a fully automated, straight-through data-securitisation workflow. This method mirrors the stages shown in the diagram and removes the need for external extracts, custom scripts, or manual intervention.
The process operates as follows:
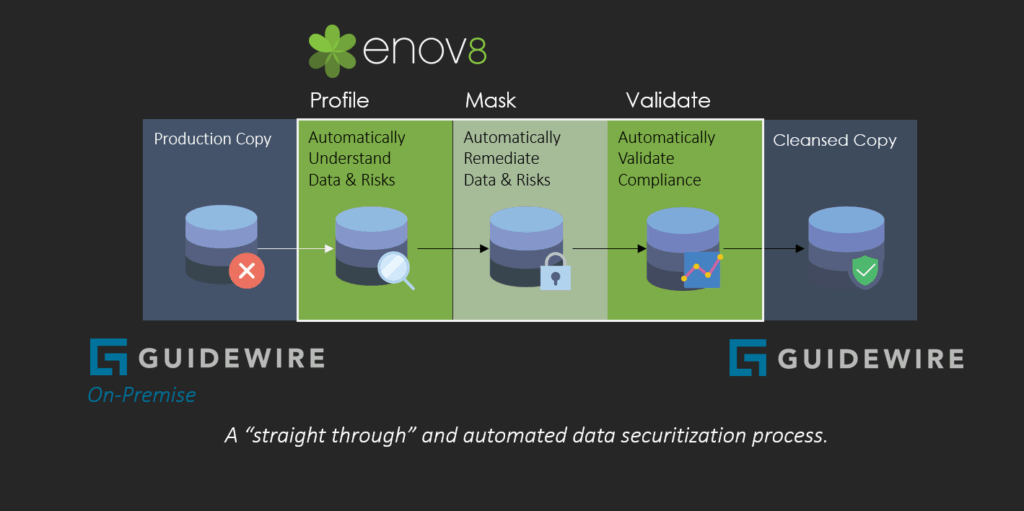
1. Profile – Automatically Understand Data & Risks
Enov8 analyses the freshly cloned Guidewire database in situ, identifying PII, PCI, and other regulated data elements.
The platform automatically detects sensitive fields, assesses risk levels, maps relationships, and builds a complete sensitivity profile across PolicyCenter, BillingCenter, ClaimCenter, and integrated schemas.
2. Mask – Automatically Remediate Data & Risks
Based on the profiling results, Enov8 automatically generates the required masking algorithms and applies them directly to the database.
The platform ensures deterministic replacement, preserves referential integrity across modules, and uses built-in libraries of masking, tokenisation, and transformation methods suitable for insurance data structures.
3. Validate – Automatically Validate Compliance
After masking completes, Enov8 executes built-in compliance and integrity validation.
This confirms that all sensitive data has been effectively anonymised, all relationships remain intact, data types adhere to expected formats, and the Guidewire applications continue to behave as expected.
4. Deliver a Cleansed, Fully Compliant Test Copy
Once validated, the environment is released as a secure, production-like instance suitable for development, QA, training, or support teams.
Because the entire process is automated, organisations achieve consistent, compliant data refreshes without manual rework or delays.
Advantages of the direct DB method:
- Faster and operationally simpler.
- Full automation through Enov8’s environment provisioning engine.
- Broader coverage across integrated databases and legacy sources.
- No need for intermediary extracts unless required for governance.
Setting Up Data Masking for Guidewire: A Practical End-to-End Process
Regardless of the hosting model, the disciplined process remains the same.
1. Identify Sensitive Data
Create a complete inventory of PII, financial, and health-related fields across Guidewire modules. Include structured and unstructured data.
2. Classify and Catalog Data Sources
Map all data flows, including external systems, reporting environments, and downstream integrations.
3. Define Masking Rules
Develop a ruleset covering names, addresses, IDs, payment data, emails, phone numbers, and free-text fields. Ensure the rules are deterministic and version-controlled.
4. Apply Masking Transformations
- SaaS: Run masking within controlled extract–mask–load pipelines.
- On-premise: Apply masking directly to the refreshed non-production database.
5. Validate Data Integrity
Confirm that referential and functional integrity remain intact. Run regression tests and sample checks for realism.
6. Maintain and Monitor
Treat masking as an ongoing discipline. Update rules as Guidewire releases new features, fields, or schema changes.
Common Challenges and How to Address Them
- Maintaining referential integrity across the three major Guidewire modules.
- Ensuring consistent masking across external data integrations (CRMs, payments, analytics).
- Avoiding performance bottlenecks during environment refresh cycles.
- Preserving realism while ensuring full anonymization.
Enov8 addresses these challenges through centralized governance, automated pipelines, referential-aware masking, and integrated environment management.
Best Practices for Effective Guidewire Data Masking
- Centralize masking policies across all non-production environments.
- Use standardized templates and deterministic rules.
- Integrate masking into refresh and CI/CD workflows.
- Maintain audit trails for compliance and traceability.
- Validate application behavior after every masking cycle.
- Review and update rules as Guidewire environments evolve.
Tools and Technologies to Support Guidewire Data Masking
While organizations may attempt masking using manual scripts or ad-hoc ETL processes, this quickly becomes unsustainable at scale.
Dedicated platforms such as Enov8 enable:
- Centralized masking governance.
- Consistent and repeatable transformations.
- Automated pipeline execution (SaaS).
- Direct database masking (on-premise).
- Auditability across environments.
- Integration into enterprise environment and release management practices.
These capabilities reduce risk, strengthen compliance, and streamline the provisioning of safe, production-like test environments.

Key Takeaways
- Guidewire data masking is essential to protect sensitive insurance data across the development lifecycle.
- The right masking method depends on the hosting model:
- SaaS: Use an Extract–Mask–Load pipeline.
- On-premise: Mask directly within the database.
- Enov8 supports both models with standardized rules, automation, and governance.
- Effective masking improves compliance, reduces operational risk, and accelerates testing.
- Integrating masking with environment and release management ensures safe, reliable test data at every refresh.
