
In the ever-evolving landscape of software development and testing, one crucial component often stands as the linchpin between success and failure: test data.
Test Data serves as the lifeblood of quality assurance, enabling developers and testers to scrutinize software applications for vulnerabilities, errors, and optimal functionality.
However, the journey from concept to deployment is not without its challenges, with questions of data privacy, accuracy, and realism looming large on the horizon.
In this examination of Test Data Management (TDM), we explore the nuanced world of generating, protecting, and using test data.
We discover how an innovative method that blends the creativity of synthetic data with the protective measures of masked real data can lead to exceptional advancements in test data practices. Central to this is the pivotal choice between masked real data and synthetic data.

The Role of Test Data in Software Testing
In the realm of software development, testing is a critical phase that ensures the final product meets user expectations and functions flawlessly.
At the heart of effective software testing lies test data. This is the information, both inputs and expected outputs, that is used to assess how a piece of software performs under various conditions.
Why Test Data Is Essential:
1. Comprehensive Coverage
Test data is indispensable for achieving comprehensive test coverage. It enables the evaluation of various scenarios, from routine operations to edge cases and error conditions.
Without diverse and representative test data, it’s impossible to assess how well software will perform in the real world.
2. Bug Identification
3. Performance Assessment
Software testing involves evaluating not only correctness but also performance. Test data provides the basis for assessing how well a system handles different workloads, data volumes, and concurrent users. Without realistic test data, it’s challenging to predict how the software will perform in production.
Identifying Potential Issues Before Deployment
1. Early detection of issues
Test data allows for early detection and resolution of issues, preventing costly and reputation-damaging problems from emerging in the production environment.
2. Reducing post-deployment risks
By thoroughly testing with representative data, organizations can minimize the risks of software failures, data breaches, and security vulnerabilities after deployment.
The Challenges of Test Data Management
While the importance of test data is undeniable, managing it effectively presents numerous challenges. Here, we delve into the complexities and limitations associated with test data management:
Using Real Production Data for Testing:
1. Data Privacy Concerns
One of the primary challenges is dealing with sensitive and confidential information. Using real production data in testing can inadvertently expose personal or sensitive details, leading to privacy breaches and potential legal ramifications.
2. Data Consistency
Production data is often dynamic and constantly changing. Test environments require consistent and stable data for meaningful testing. Synchronizing and maintaining consistent real data in a testing environment can be a logistical nightmare.
Data Masking and Privacy Regulations:
1. Data Masking
2. Privacy Regulations
In today’s data-centric world, privacy regulations like GDPR (General Data Protection Regulation) and HIPAA (Health Insurance Portability and Accountability Act) impose strict guidelines on the handling and protection of personal and sensitive data. Failure to comply can result in hefty fines and damage to an organization’s reputation.
Effective test data management requires navigating these challenges and finding innovative solutions that strike a balance between realistic testing and safeguarding sensitive information.
Fake Data vs. Real Data: Pros and Cons
As we delve deeper into the intricacies of test data management, it’s essential to weigh the advantages and disadvantages of two primary approaches: using fake data and relying solely on real data for testing.
Advantages of Using Fake Data:
1. Data Privacy Assurance
2. Predictable and Controlled
Fake data provides complete control over the testing environment. Testers can create specific scenarios and edge cases, ensuring consistent and reproducible testing conditions.
3. Unlimited Variations
With fake data, there are no limitations on the variations and scenarios that can be tested. Testers can simulate extreme conditions, rare events, or unique scenarios that may be challenging to replicate with real data.
Disadvantages of Using Fake Data:
1. Lack of Realism
The primary drawback of fake data is its lack of realism. While it can mimic data structures and formats, it may not accurately represent the intricacies and complexities of real-world data.
2. Limited Real-world Validation
Fake data may not uncover issues that are specific to real-world data interactions. Testing solely with fake data may overlook potential problems that could arise when the software encounters genuine user-generated data.
Advantages of Using Real Data:
1. Real-world Validation
Testing with real data provides an opportunity to validate how the software performs with actual user-generated data. It can uncover issues that might not be apparent when using fake data.
2. High Realism
Real data reflects the actual complexities and nuances of the production environment, making it valuable for assessing real-world performance and behavior.
Disadvantages of Using Real Data:
1. Data Privacy Risks
The use of real data carries inherent data privacy risks, as mentioned earlier. Mishandling or exposing sensitive information can lead to severe consequences.
2. Data Consistency
Maintaining a consistent and up-to-date copy of real data for testing can be challenging and resource-intensive.
In practice, the ideal approach often lies in finding a balance between fake data and real data, leveraging the strengths of each while mitigating their respective weaknesses.
The Power of Data Masking
In the realm of test data management, data masking emerges as a potent solution to address the challenges associated with using real data while safeguarding data privacy.
Data masking involves the transformation of sensitive information within datasets, rendering it unidentifiable and unusable by unauthorized individuals.
The Concept of Data Masking:
Data De-identification
Data masking techniques include methods such as tokenization, encryption, and data substitution. These techniques ensure that sensitive data elements are replaced with fictitious but structurally similar data, maintaining the format and relationships within the dataset.
Preserving Data Relationships
Effective data masking not only obscures individual data points but also ensures that the relationships between data elements remain intact. This is crucial for maintaining the functionality of the application during testing.
Role in Protecting Sensitive Information During Testing:
1. Compliance with Privacy Regulations
Data masking aligns with privacy regulations by ensuring that sensitive data is never exposed in its original form during testing, thus mitigating privacy risks.
2. Safe Testing Environments
It enables organizations to create safe and controlled testing environments where testers can work confidently with datasets without fear of data breaches.
Data masking acts as a bridge between the need for realism in testing and the imperative of data privacy. In the following section, we will explore how combining fake data with masked real data can offer a holistic solution that overcomes the limitations of both approaches.
Blending Fake Data with Masked Real Data
As we navigate the complex landscape of test data management, a strategic approach emerges that leverages the strengths of both fake data and masked real data. This approach involves blending the two to create a harmonious testing environment that balances realism and data privacy.
Benefits of Combining Fake Data and Masked Real Data:
1. Realistic Scenarios with Privacy
By combining the ingenuity of fake data and the security of masked real data, organizations can create realistic testing scenarios while ensuring the protection of sensitive information.
2. Comprehensive Testing
Testers gain the ability to conduct comprehensive testing that reflects the complexities of real-world data interactions. This approach allows for the identification of issues specific to real data without compromising privacy.
3. Flexibility and Control
Blending these two types of data provides flexibility and control. Organizations can choose where to use real data and where to incorporate fake data, depending on the testing objectives and privacy considerations.
Creating the Balance:
1. Data Mapping
Careful mapping of real data elements to their corresponding masked or fake counterparts is essential. This mapping ensures that the relationships and dependencies within the data remain intact.
2. Selective Use
Determine which parts of the data need to be masked and which can be replaced with fake data. The balance should align with the organization’s privacy policies and the testing goals.
Ensuring Realism without Compromising Privacy:
1. Scenario Diversity
Organizations can create a wide range of test scenarios that encompass real-world complexities without exposing sensitive data. This approach enables more accurate predictions of how the software will perform in the field.
2. Privacy Assurance
With the use of data masking, privacy concerns are addressed, and organizations can confidently carry out testing activities without risking data breaches or regulatory non-compliance.
Best Practices for Test Data Management
Effective test data management is essential for achieving optimal testing outcomes. Here, we outline a set of best practices that organizations can follow to streamline the process of test data generation, masking, and storage while maintaining data quality and consistency.
1. Data Generation:
- Data Reusability: Create reusable test data sets to save time and resources. Well-structured, reusable data sets enable consistent testing across different scenarios.
- Data Variation: Generate diverse data sets to cover a wide range of testing scenarios. Variability in data helps identify and address different application behaviors.
2. Data Masking:
- Granularity Control: Determine the level of granularity for data masking. Some data elements may require more extensive masking than others based on their sensitivity.
- Audit Trails: Implement audit trails to track data access and usage during testing. This ensures accountability and compliance with privacy regulations.
3. Data Storage:
- Secure Storage: Store test data securely, ensuring that only authorized personnel have access. Encryption and access controls should be in place to protect sensitive data.
- Data Refresh: Regularly refresh / provision test data to ensure it remains relevant and up-to-date. Stale or outdated data can lead to inaccurate testing results.
4. Data Quality and Consistency:
- Data Validation: Validate test data for accuracy and consistency before and after masking. Data quality is crucial for reliable testing outcomes.
- Data Governance: Establish data governance practices to maintain data integrity throughout the testing lifecycle.
By adhering to these best practices, organizations can navigate the complexities of test data management effectively, ensuring that their testing processes are both robust and compliant with data privacy regulations.
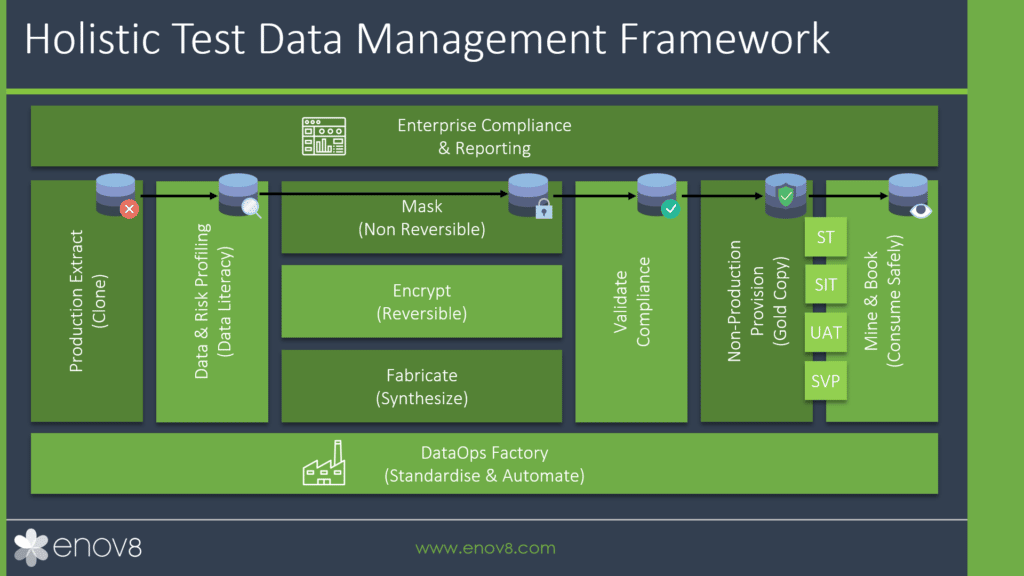
Tools and Solutions for Test Data Management
In the dynamic landscape of software testing, having the right tools and solutions can significantly enhance test data management efficiency and effectiveness.
Various software applications and platforms have emerged to address the challenges associated with test data generation, masking, and overall management. One notable solution in this arena is Enov8 TDM.
Enov8 TDM – Revolutionizing Test Data Management
1. Comprehensive Data Management
Enov8 TDM provides an all-encompassing platform for test data management. It facilitates various processes including data generation, masking, provisioning, and data booking management, streamlining the entire test data lifecycle.
2. Data Masking and Compliance
The platform ensures robust data masking capabilities, crucial for safeguarding sensitive information. This feature is particularly important for compliance with data privacy regulations, allowing organizations to conduct safe testing without exposing sensitive data.
3. Data Bookings
Enov8 TDM enhances the efficiency of data bookings. It simplifies the reservation and provisioning of test data, ensuring its availability for testing teams as required.
4. Integration and Automation
With seamless integration capabilities, Enov8 TDM works harmoniously with existing testing tools and environments. This integration facilitates the automation and orchestration of test data provisioning and masking.
5. Data Profiling and Analysis
The tool also excels in data profiling and analysis, providing valuable insights into test data. This enhances the development of more effective testing strategies.
Other Test Data Management Tools:
- Delphix: Delphix is another notable player in the test data management space, offering data virtualization and masking solutions for secure and efficient test data management.
- Informatica TDM: Informatica provides a comprehensive test data management platform that includes data profiling, masking, subsetting, and synthetic data generation.
- IBM InfoSphere Optim: IBM’s InfoSphere Optim offers a range of test data management capabilities, including data subsetting, data masking, and test data generation.
Selecting the right test data management tool depends on the specific needs and requirements of your organization.
Conclusion
In the ever-evolving landscape of software testing, the mastery of effective test data management is paramount.
The art of striking the perfect equilibrium between fake data and masked real data empowers organizations to scrutinize their software applications with exacting precision while preserving the integrity, privacy, and security of sensitive information.
By steadfastly following best practices and harnessing the capabilities of the right tools and techniques, you can elevate your test data management strategy and set the stage for a future filled with successful and secure software deployments.

Author Jane Temov
Jane Temov is an IT Environments Evangelist at Enov8, specializing in IT and Test Environment Management, Test Data Management, Data Security, Disaster Recovery, Release Management, Service Resilience, Configuration Management, DevOps, and Infrastructure/Cloud Migration. Jane is passionate about helping organizations optimize their IT environments for maximum efficiency.